Llama-3-Taiwan-70B 是一个基于 Llama-3 架构在大规模繁体中文和英文语料库上微调的 70B 参数模型。它在各种繁体中文自然语言处理基准测试中展现出最先进的性能。
130 拉取 更新于6周前
更新于6周前
6周前
4b05ee64ec2b · 43GB
README
来源:https://hugging-face.cn/yentinglin/Llama-3-Taiwan-70B-Instruct

🚀 演示网站
在 twllm.com 交互式尝试Llama-3-Taiwan
⚔️ 聊天机器人竞技场
参与激动人心的 聊天机器人竞技场,与其他聊天机器人竞争!
🚀 我们兴奋地推出 Llama-3-Taiwan-70B!Llama-3-Taiwan-70B 是一个 70B 参数模型,使用 Llama-3 架构在大量繁体中文和英文数据集上进行微调。它在各种繁体中文自然语言处理基准测试中表现出最先进的性能。
该模型使用 NVIDIA NeMo™ 框架和以 NVIDIA DGX H100 系统构建的 NVIDIA Taipei-1 进行训练。
Llama-3-Taiwan-70B 的训练计算和数据得到了以下机构的大力支持:长庚纪念医院、长荣集团、Legalsign.ai、NVIDIA、和硕联合科技、TechOrange、光宝科技(按字母顺序排列)。
我们感谢数据提供商、团队成员和顾问在该模型开发中的贡献,包括贡献,特别是shasha77为YouTube脚本来料和教材,台湾人工智能实验室提供当地媒体内容,Ubitus K.K.提供游戏内容,陈云南(Vivian)教授的指导和建议,陈韦霖领导我们的预训练数据管道,林子涵进行合成数据处理,高长胜提高我们的合成数据质量,以及陈康杰清理指令遵循数据。
模型摘要
Llama-3-Taiwan-70B 是一个针对繁体中文和英文用户进行微调的大型语言模型。它在语言理解、生成、推理和多轮对话方面具有强大的能力。主要特点包括
- 70B 个参数
- 语言:繁体中文 (zh-tw),英语 (en)
- 在高质量繁体中文和英语语料库上进行微调,涵盖法律、制造、医疗和电子领域的一般知识以及行业知识
- 8K 上下文长度
- 在 Llama-3 许可证下释放的开放模型
训练细节
- 训练框架:[NVIDIA NeMo](https://www.nvidia.com/zh-tw/ai-data-science/products/nemo/),[NVIDIA NeMo Megatron](https://docs.nvda.net.cn/nemo-framework/user-guide/latest/nemotoolkit/nlp/megatron.html)
- 推理框架:[NVIDIA TensorRT-LLM](https://github.com/NVIDIA/TensorRT-LLM)
- 基模型:[Llama-3 70B](https://llama.meta.com/llama3/)
- 硬件:[NVIDIA DGX H100](https://www.nvidia.com/zh-tw/data-center/dgx-h100/) 在台北-1
- 上下文长度:8K 令牌([128k 版本](https://hugging-face.cn/yentinglin/Llama-3-Taiwan-70B-Instruct-128k))
- 批次大小:每步 2M 令牌
评估
查看开放 TW LLM 排行榜以获取完整和更新的列表。
| 模型 | TMLU | 台湾真实问答 | 法律评估 | TW MT-Bench | 长上下文 | 函数调用 | TMMLU+ |
|---|---|---|---|---|---|---|---|
| 学科知识 | 台湾本地化测试 | 台湾法律考题 | 中文多轮对话 | 长文本支持 | 函数调用 | ||
| yentinglin/Llama-3-Taiwan-70B-Instruct | 74.76% | 80.95% | 68.42% | 7.54 | 128k 版本 | ✅ | 67.53% |
| yentinglin/Llama-3-Taiwan-70B-Instruct-DPO | 74.60% | 81.75% | 70.33% | - | - | ✅ | - |
| yentinglin/Llama-3-Taiwan-70B-Instruct-128k | 73.01% | 80.16% | 63.64% | - | - | ✅ | - |
| yentinglin/Llama-3-Taiwan-8B-Instruct | 59.50% | 61.11% | 53.11% | 7.21 | 128k 版本 | ✅ | 52.28% |
| yentinglin/Llama-3-Taiwan-8B-Instruct-DPO | 59.88% | 59.52% | 52.63% | - | - | ✅ | - |
| yentinglin/Llama-3-Taiwan-8B-Instruct-128k | - | - | - | - | - | ✅ | - |
| Claude-3-Opus | 73.59% (5 Shot) | 69.84% | 60.29% | - | 200k | ✅ | - |
| GPT4-o | 65.56% (0 Shot), 69.88% (5 Shot) | 76.98% | 53.59% | - | 128k | ✅ | - |
| GPT4-turbo | 70.42% (5 Shot) | - | - | - | 128k | ✅ | 60.34%^ |
| Gemini-Pro | 61.40% (5 Shot) | - | - | - | 1000k | ✅ | 49.92%^ |
| GPT-3.5-turbo-1106 | 49.37% (5 Shot) | - | - | 7.1 | 128k | ✅ | 41.76%^ |
| Qwen1.5-110B-Chat | 75.69% | 66.67% | 49.28% | - | 32k | ✅ | 65.81% |
| Yi-34B-Chat | 73.59% | 71.43% | 55.02% | 6.9 | 200k | ✅ | 64.10% |
| Meta-Llama-3-70B-Instruct | 70.95% | 65.08% | 52.63% | - | 8k | ✅ | 62.75% |
| Mixtral-8x22B-Instruct-v0.1 | 55.57% | 52.38% | 44.98% | - | 64k | ✅ | 52.16% |
| Breexe-8x7B-Instruct-v0_1 | - | - | - | 7.2 | 8k | ❓ | 48.92% |
| c4ai-command-r-plus | 62.87% | 64.29% | 34.45% | - | 128k | ✅ | 49.75% |
| Meta-Llama-3-8B-Instruct | 55.81% | 46.83% | 35.89% | - | 8k | ✅ | 43.38% |
| Breeze-7B-Instruct-v1_0 | 55.57% | 52.38% | 39.23% | 6.0 | 32k | ❓ | 41.77% |
| Llama3-TAIDE-LX-8B-Chat-Alpha1 | 47.30% | 50.79% | 37.80% | - | 8k | ❓ | 39.03% |
| Phi-3-mini-4k-instruct | 40.97% | 37.30% | 27.27% | - | 4k | ❓ | 33.02% |
数字默认为0 Shot。
^ 从原始数据集中取最接近的匹配数字。
稻草寻针评估
“稻草寻针 出师表”评估测试模型在大块文本中定位和回忆嵌入的重要信息的能力,使用经典的中文文献《出师表》。
要运行评估,请使用脚本。
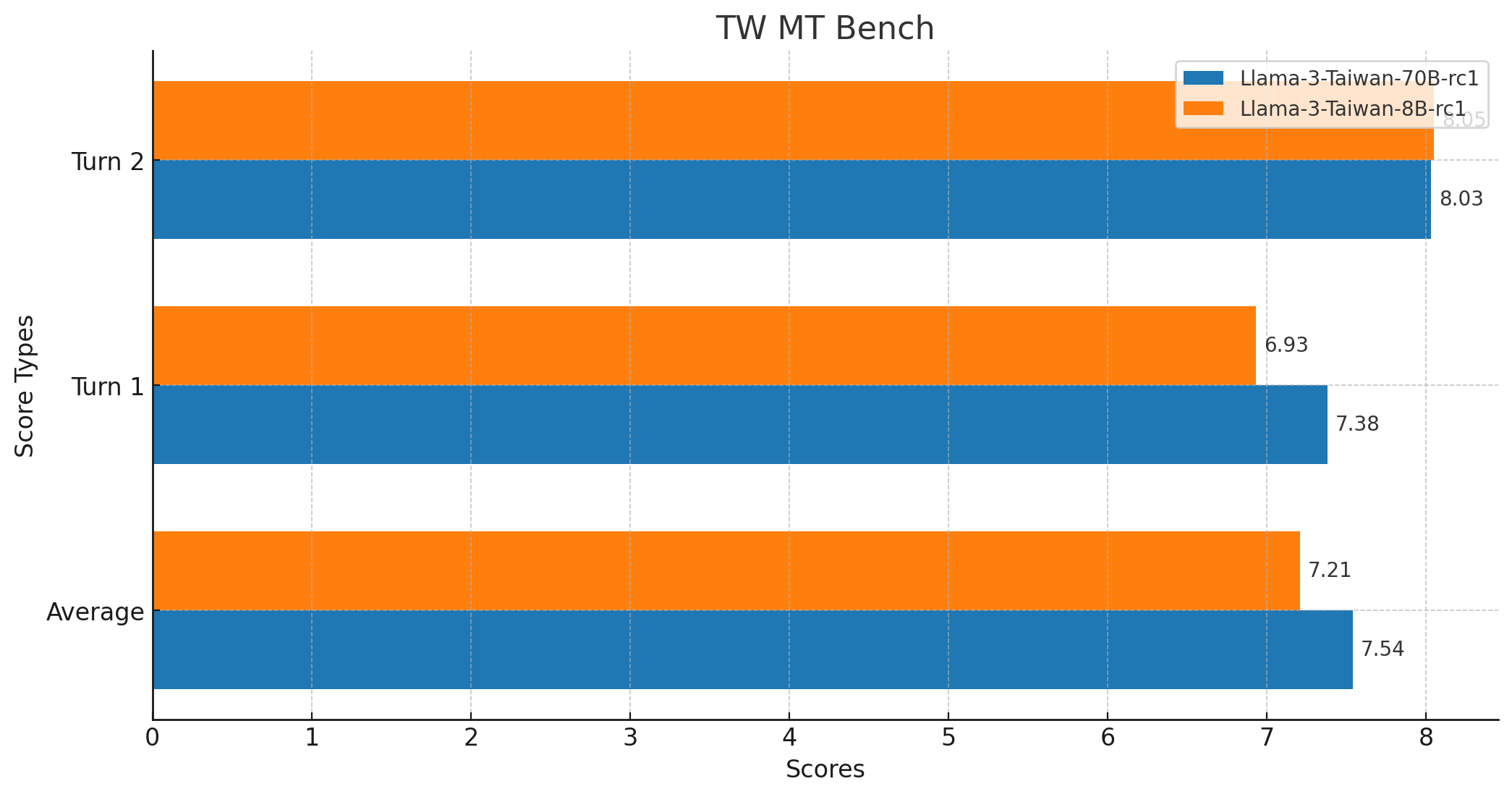
TW MT-Bench 分数
- 平均分数:7.5375
- 最高分数:10
- 最低分数:1
- 中位数分数:9.0
- 标准差:3.0349783771882133
- 总分数:160
- 模型响应
- GPT-4 评估
- 从
mtkresearch/TCEval分支代码中获取,修复了错误
用例
Llama-3-Taiwan-70B 可用于多种多样繁体中文和英文的NLP任务,包括:
1. 多轮对话
System: You are an AI assistant called Twllm, created by TAME (TAiwan Mixture of Expert) project. User: 嗨,你好! Assistant: 你好!我今天可以如何協助你? User: 就想聊天而已.... Assistant: 當然,我很樂意和你聊天!有什麼特別想談論的嗎?
2. RAG(检索增强生成)
演示:可以在[twllm.com](https://twllm.com/)上打开“Search Web” System: You are an AI assistant called Twllm, created by TAME (TAiwan Mixture of Expert) project. User: 明天台大天氣如何? Assistant: 根據天氣預報,明天台大天氣為陣雨。低溫 24°C。10 到 15 公里/小時 的 東 風 。降雨機率為 40%。
3. 格式化输出,语言理解,实体识别,函数调用
如果您对函数调用感兴趣,我强烈推荐使用[有约束解码](https://hugging-face.cn/docs/text-generation-inference/basic_tutorials/using_guidance)来启用“json模式”。例如,来自李宏毅的《2024春季生成式AI导论》中的HW7 System: You are an AI assistant called Twllm, created by TAME (TAiwan Mixture of Expert) project.
User: 您是電影評論分析師,負責情緒分析。
分析每個被評論的句子,評估句子中每個字和標點符號的重要性,
並且將結果使用 tuple 的結構列出。
tuple 值的範圍介於 -1 (負向) 到 1 (正向) 之間,
然後,將評論分類為正向 (1) 或負向 (-1)。
這些需要被評論的句子,包含在 標籤中間。
輸出範例:
[(<單字或標點符號>, ), ...]
根據外媒報導,宏都拉斯在去年3月與台灣斷交,並轉往與中國建交之後,卻遲遲等不到中國的金援,談好要進口宏都拉斯的白蝦也拖延許久,甚至還將白蝦價格殺價至過往與台灣交易的半價,再加上墨西哥同時也中斷了與宏國的白蝦貿易,對當地蝦農可說是雪上加霜。
Assistant: [('根據', 0.2), ('外媒', 0.1), ('報導', -0.1), (',', 0.05), ('宏都拉斯', -0.3), ('在去年3月與台灣斷交, ', -0.5), ('並轉往與中國建交之後, ', -0.4), ('卻遲遲等不到中國的金援, ', -1),
('談好要進口宏都拉斯的白蝦也拖延許久, ', -1),
(',甚至還將白蝦價格殺價至過往與台灣交易的半價,再加上墨西哥同時也中斷了與宏國的白蝦貿易,對當地蝦農可說是雪上加霜。 ',-1)]
-1
开始使用
注意:将这些设置为停止令牌:[“USER:”, “ASSISTANT:”, “<|im_end|>”, “<|eot_id|>”, “<|end_of_text|>”]
Hugging Face Transformers库
您可以使用Hugging Face Transformers库与Llama-3-Taiwan-70B一起使用
import torch
from transformers import pipeline, StoppingCriteria
# Define a custom stopping criteria class
class EosListStoppingCriteria(StoppingCriteria):
def __init__(self, eos_sequence=[128256]):
self.eos_sequence = eos_sequence
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
last_ids = input_ids[:, -len(self.eos_sequence):].tolist()
return self.eos_sequence in last_ids
# Initialize the model with automatic device mapping
llm = pipeline("text-generation", model="yentinglin/Llama-3-Taiwan-70B-Instruct", device_map="auto")
tokenizer = llm.tokenizer
# Define a conversation example
chat = [
{"role": "system", "content": "You are an AI assistant called Twllm, created by TAME (TAiwan Mixture of Expert) project."},
{"role": "user", "content": "你好,請問你可以完成什麼任務?"},
{"role": "assistant", "content": "你好,我可以幫助您解決各種問題、提供資訊並協助完成多種任務。例如:回答技術問題、提供建議、翻譯文字、尋找資料或協助您安排行程等。請告訴我如何能幫助您。"},
{"role": "user", "content": "太棒了!"}
]
flatten_chat_for_generation = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
"""
<|im_start|>user
You are an AI assistant called Twllm, created by TAME (TAiwan Mixture of Expert) project.<|im_end|>
<|im_start|>user
你好,請問你可以完成什麼任務?<|im_end|>
<|im_start|>assistant
你好,我可以幫助您解決各種問題、提供資訊和協助您完成許多不同的任務。例如:回答技術問題、提供建議、翻譯文字、尋找資料或協助您安排行程等。請告訴我如何能幫助您。<|im_end|>
<|im_start|>user
太棒了!<|im_end|>
<|im_start|>assistant
"""
# Generate a response using the custom stopping criteria
output = llm(flatten_chat_for_generation, return_full_text=False, max_new_tokens=128, top_p=0.9, temperature=0.7, stopping_criteria=[EosListStoppingCriteria([tokenizer.eos_token_id])])
print(output[0]['generated_text'])
"謝謝!很高興能夠為您服務。如果有任何其他需要協助的地方,請隨時與我聯繫。我會盡最大努力為您提供所需的支援。"
vLLM
启动服务器
export NUM_GPUS=4
export PORT=8000
docker run \
-e HF_TOKEN=$HF_TOKEN \
--gpus '"device=0,1,2,3"' \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-p "${PORT}:8000" \
--ipc=host \
vllm/vllm-openai:v0.4.0.post1 \
--model "yentinglin/Llama-3-Taiwan-70B-Instruct" \
-tp "${NUM_GPUS}"
示例客户端代码,或者您可以使用任何与OpenAI-API兼容的客户端
# pip install "openai>=1.0.0"
from openai import OpenAI
# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "https://:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="yentinglin/Llama-3-Taiwan-70B-Instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a joke."},
]
)
print("Chat response:", chat_response)
尽情探索Llama-3-Taiwan-70B的功能!我们期待看到您用这个强大的开源模型创造出什么。如果您有任何疑问或反馈,请告知我们。
贡献者
- 陈允旭(陈慧仁)教授,在整个项目中的指导和咨询。
- 陈韦霖,领导我们的预训练数据流程。
- 林子涵,进行合成数据生成。
- 曹长生,提高我们的合成数据质量。
- 陈康杰,清理遵循指令的数据。
- 陈敏怡和许绍 timestep)),收集化学工程数据和基准。
- 马中坜,郭俊彦和曾嘉轩,收集制造和电气工程数据、基准和项目管理。
引用
@article{DBLP:journals/corr/abs-2311-17487,
author = {Yen{-}Ting Lin and
Yun{-}Nung Chen},
title = {Taiwan {LLM:} Bridging the Linguistic Divide with a Culturally Aligned
Language Model},
journal = {CoRR},
volume = {abs/2311.17487},
year = {2023},
url = {https://doi.org/10.48550/arXiv.2311.17487},
doi = {10.48550/ARXIV.2311.17487},
eprinttype = {arXiv},
eprint = {2311.17487},
timestamp = {Tue, 05 Dec 2023 14:40:42 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2311-17487.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
@article{DBLP:journals/corr/abs-2403-20180,
author = {Po{-}Heng Chen and
Sijia Cheng and
Wei{-}Lin Chen and
Yen{-}Ting Lin and
Yun{-}Nung Chen},
title = {Measuring Taiwanese Mandarin Language Understanding},
journal = {CoRR},
volume = {abs/2403.20180},
year = {2024},
url = {https://doi.org/10.48550/arXiv.2403.20180},
doi = {10.48550/ARXIV.2403.20180},
eprinttype = {arXiv},
eprint = {2403.20180},
timestamp = {Wed, 10 Apr 2024 17:37:45 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2403-20180.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}